Don't be a stump
It's often said that two brains are better than one. And if those brains are better at doing a task than purely guessing, you've got yourself the making of Boosting, a very powerful concept in Machine Learning.

Boosting is a way to crowdsource some prediction or classification, rather than trying to figure it out yourself. If it seems intuitive, that's because it is.
Today I'm going to introduce a specific type of boosting algorithm, called Adaboost.
Imagine trying to decide if a politician is a Democrat or a Republican. Each party has certain attributes that are associated with it. Democrats are more likely to invest in public infrastructure. Republicans may consider that a waste of resources and instead are more likely to want to lower taxes for the wealthy.
The question is, given enough different politicians, can we learn a general way to distinguish between them? It gets tricky when some politicians cross party lines and muddy the waters.
Let's continue with our example. Imagine we have 100 politicians (data points) and want to classify them as Democrats or Republicans (2 classes). Let's also assume that we have 10 voters (classifiers) to help us out.
Now, instead of asking them all at once, we ask them sequentially. So first we ask Person A. Person A does some homework and makes predictions for the 100 politicians. Let's say she correctly classifies 70 and incorrectly classifies 30.
Next up, Person B. Knowing where A made mistakes, B focuses specifically on the 30 people A got wrong. Then after some research, B makes his predictions. He gets all of the 30 right, and 20 others as well, but that still means he got 50 politicians wrong.
Then comes C. C focuses on the 50 that were just now incorrectly classified by B, but also pays some mind to the 30 that A originally got wrong. Then Person C goes ahead and make his predictions.
This continues until all 10 people have made their predictions. Since every person gets to see where the previous people went wrong, they can adapt their research to focus on the hardest politicians to classify. Clearly there is something wacky about these bi-partisan politicians that make them harder to classify. Voters can't stick to the same old script (low taxes = Republican, pro-choice = Democrat). They have to figure out new, complex rules. This adapting feature of the algorithm is the Ada, in Adaboost.
In the end, we're left with each politician getting a certain number of +1s (if voted as Democrat) and -1s (if voted Republican). The sum of the +1s and -1s is the politician's score. Finally, we need to account for the fact that not every voter is treated equally (sadly mirroring reality). Some predicted more accurately than others, and in tallying up the final numbers, their vote should be given more weight.
So one politician might get a score of +4 (meaning 7 people voted Democrat and 3 people voted Republican). Another politician gets a score of -6, etc... Our final classifier implicitly "learns" what is it about all these politicians that led to their scores. Some might be staunch socialists, some might be hardcore libertarians, some might fall somewhere in the middle, including the hard-to-classify bi-partisan ones. Now our classifier can go out in the world and, using everything it learned, can hopefully classify new politicians accurately.
So that's the Adaboost algorithm, which is a beast in the Machine Learning literature. Now let's see it in action. Say you want to classify the following data set:
It looks super messy. It's not linearly separable, and while we could consider elevating it to higher dimensions and then solving it, we'll lose some of the interpretability of our data that way. It's hard to know what's happening in 100 dimensional space. So let's hang out in 2D space where we can see stuff happen.
Now, the first step of Adaboost is to get a weak classifier. A common choice is a Decision Tree Stump. If you think of a decision tree as having many branches, a stump is just one split. Class A or Class B. Clearly this guy is not sufficient for any practical uses. He's like your average voter. Well meaning, but at times just useless.
Binary partition
We can see where it went wrong. The misclassified points are like our bi-partisan politicians. We need more sophisticated rules for them. So, we tell the next classifier to focus on the ones we got wrong. We do this by exaggerating their errors and feed in the re-weighted dataset into the next voter, i.e. stump. Here's how a bunch of stumps do:
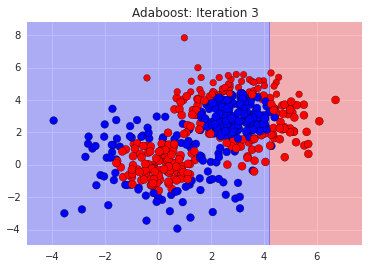
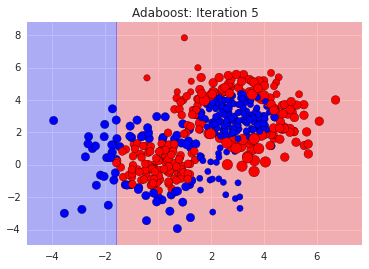
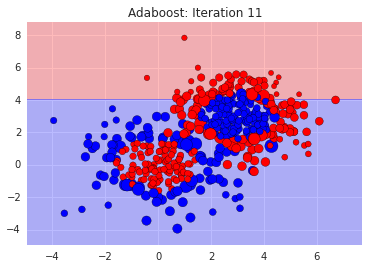
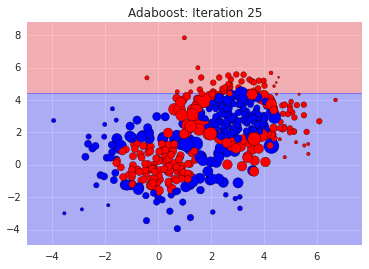
You can see the sizes of the data points adjusting to reflect how easy or hard they are to get right. And you'll notice that each classifier on its own is bad, since its just a straight line. In the end however, after say, 500 weak classifiers, we can add them all up resulting in our final strong classifier:
Much better! Indeed, all we did was combine a bunch of stumps into something that clearly fits our data very well.
To recap:
- Boosting is a "crowdsourcing" type of Machine Learning algorithm
- Adaboost is a version of Boosting that uses weak classifiers to sequentially learn things about the dataset
- The final classifier scores each data point based on the sum of the scores from each weak classifier. Each weak classifier's score is also re-weighted to reflect how good or bad that classifier did
- Trickle down economics is a joke
* Actually, the fact that its generalization error is bounded above is perhaps its most appealing quality as a Machine Learning technique. But we'll cover that in a future post.